728x90
반응형
1. tesseract install
tessertact 에서 설치합니다. (github.com/tesseract-ocr/tesseract/wiki)
사용중인 OS에 맞춰 설치하면 되며, 제가 이번에 Test할 환경은 Window x64이기 때문에 여기에 맞춰서 설치했습니다.
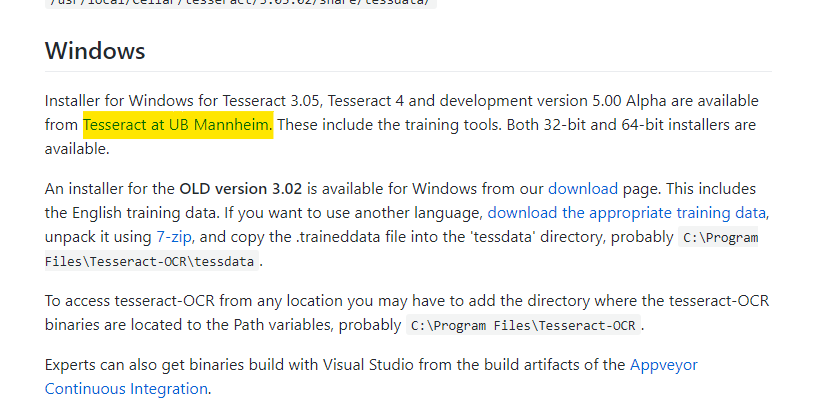
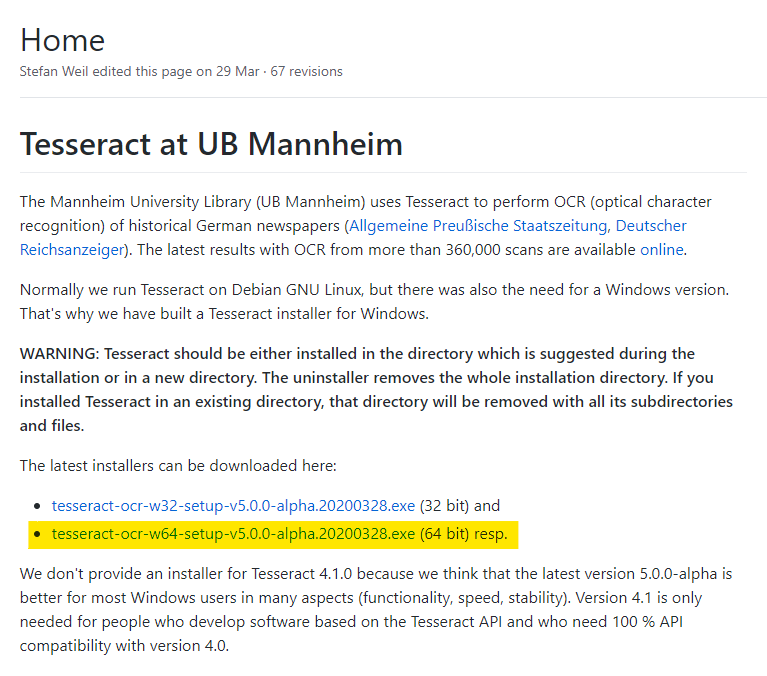
설치 중 Additional language data 를 선택하고 Korean을 추가합니다.


설치 완료 후 환경변수에 경로를 추가합니다.

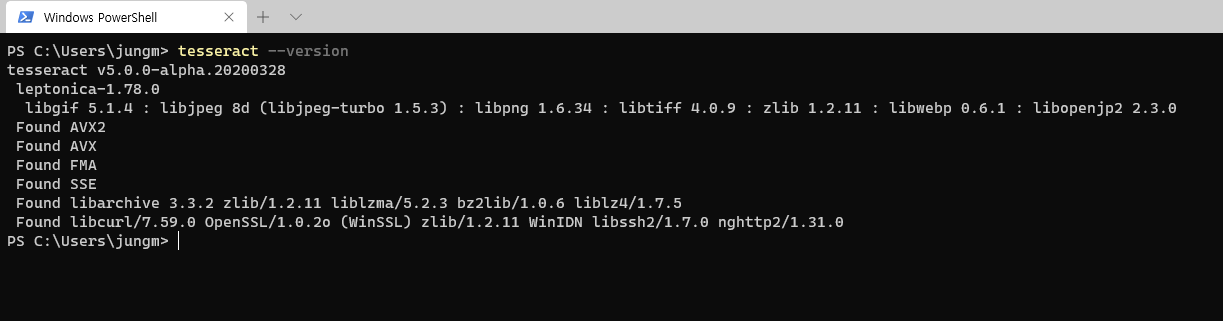
power shell 에서 설치 확인
tesseract --version
2. pytesseract install
python 에서 사용하기 위해 pytesseract를 설치한다.
pip install pytesseract
3. Python으로 테스트 진행
python code
from PIL import Image
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract'
img = Image.open('test.png')
text = pytesseract.image_to_string(img,lang='kor+eng')
print (text)아래 이미지를 가지고 테스트를 진행 했습니다.

결과...

간단하게 테스트를 했을 때, 영어와 숫자는 잘 인식이 되는 것으로 보인다.
한국어도 잘 되지만... 일부러 잘 사용하지 않는 글자인 뚫쀍 같은 글자를 추가해서 테스트를 했는데... 이런 글자는 인식하지 못했다.
이번에는 그림(?)이 있으면 어떻게 될지 궁금해서 아래와 같이 변경해서 테스트를 진행했습니다.
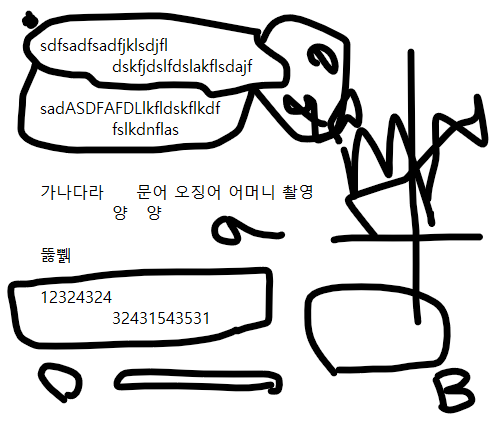
결과는...
중간에 공백이 많이 생기긴 했지만 영어랑 숫자는 영향이 많이 없네요...
다만 한글은 인식율이 떨어지는 것으로 보입니다.

반응형
'Programming' 카테고리의 다른 글
| WSL2에 도커 설치 테스트 (0) | 2020.04.01 |
|---|---|
| [Python] os 모듈의 walk를 활용한 경로 탐색 방법 (0) | 2019.07.18 |
| linux screen 사용 방법 (0) | 2019.07.10 |
| [Python] 재미삼아 만든 로또 번호 파싱 & 번호 생성기...(Web Crawling) (0) | 2019.06.16 |
| [Linux] Raspberry Pi SD Card Back-up by Win32 Disk Imager (0) | 2018.10.22 |
